Делаем сем. ядро для одной страницы и получаем ТОП в поиске
 Артём Акулов
Артём АкуловВ этой статье я поделюсь быстрым и эффективным алгоритмом сбора семантического ядра для одной страницы сайта. Наиболее логично данный метод будет применить к сайтам услуг и контентным проектам.
Семантика является фундаментом эффективного SEO.
Если фундамент так себе - результат будет хз.
Оглавление статьи:
Почему для одной страницы?
Всё просто. Многие специалисты пытаются сразу собрать семантическое ядро для всех продвигаемых страниц сайта, всех услуг, продуктов и так далее, сразу всё это кластеризовать, сделать структуру, мета-теги и всё-всё-всё.
На самом деле при таком подходе может довольно сильно страдать качество. В итоге какие-то кластеры будут продвигаться хуже, где-то топа не будет вообще, и даже ссылки с накруткой ПФ не помогут.
Детальная проработка сем. ядра для одной страницы позволяет:
- отбросить ключевые слова, по которым ранжируются сайты не в нашей весовой категории;
- выявить четкий интент;
- получить перечень схожих фраз;
- сделать сразу норм и не переделывать.
На проработку семантики под одну страницу потребуется до 30 минут.
Алгоритм работы
1. Используем сервис для работы с семантикой на свое усмотрение. Это могут быть: Ahrefs, Semrush, Keys.so, Mangools и так далее. Я на постоянке пользуюсь Ahrefs и сейчас буду использовать именно его.
2. Для примера возьмем тематику "типография" и представим, что нам нужно продвинуть сайт по этой тематике. Берем ключевое слово "типография" и начинаем анализ: выбираем регион и поисковую систему.

Приступаем к анализу данных. В первую очередь открываю вкладку "основные темы", где уже Ahrefs сгруппировал ключевые слова.

Начинаем смотреть интересующие нас фразы. На этом этапе сразу анализируем какие сайты ранжируются в SERP и не берем ключевое слово, если там нет прямых конкурентов, сайты другого типа или тематики.
Добавляем интересующие нас фразы в список внутри сервиса (в моем случае это Ahrefs) или в Excel файл, кому как удобней.
3. Сразу смотрим поисковые подсказки. В Google есть 3 трипа поисковых подсказок: из строки поиска, из нижнего блока под результатами поиска, и подсказки, которые появляются после клика на конкурента в топ-1 и возврата в SERP.
4. Сводим все ключевые слова с таблицу с параметрами: частота, сложность продвижения (KD, есть в Ahrefs), потенциал трафика (TP, есть в Ahrefs). Вот и всё, список готов, можно дальше делать структуры, ТЗ на тексты и так далее.
Нужно ли парсить ключевые слова с конкурентов?
Можно и так, но на практике сем. ядро для страницы получится не совсем полным. Не факт, что конкуренты поддерживают семантику страниц в актуальном состоянии, некоторые интересные фразы могут быть упущены.
При этом конкуренты могут ранжироваться по фразам, которых у них нет ни в текстах ни в мета-тегах, но если внедрить упущенные фразы конкурентов в свой сайт, то позиции будут выше.
Намного эффективнее отбирать ключевые слова вручную и быстро делать список на 20-30-50-100 фраз. Объёмы списка зависят от тематики. Потом можно сопоставить этот список с тем, что спарсил сервис с определенной страницы конкурента и, так сказать, ощутить разницу.
Как актуализировать сем. ядро для существующей страницы?
Актуализировать семантику на страницах сайта нужно хотя бы раз в год, а обычно это требуется раз в полугодие. В Google самая полная семантика содержится в GSC. Эти данные полностью не видит ниодин сервис.
Алгоритм актуализации покажу на небольшом сайте регионального косметологического центра.
1. Допустим, нам нужно актуализировать сем. ядро для страницы по услуге "Трихология". Заходим в GSC, затем - Эффективность. Настраиваем фильтры по URL и стране.
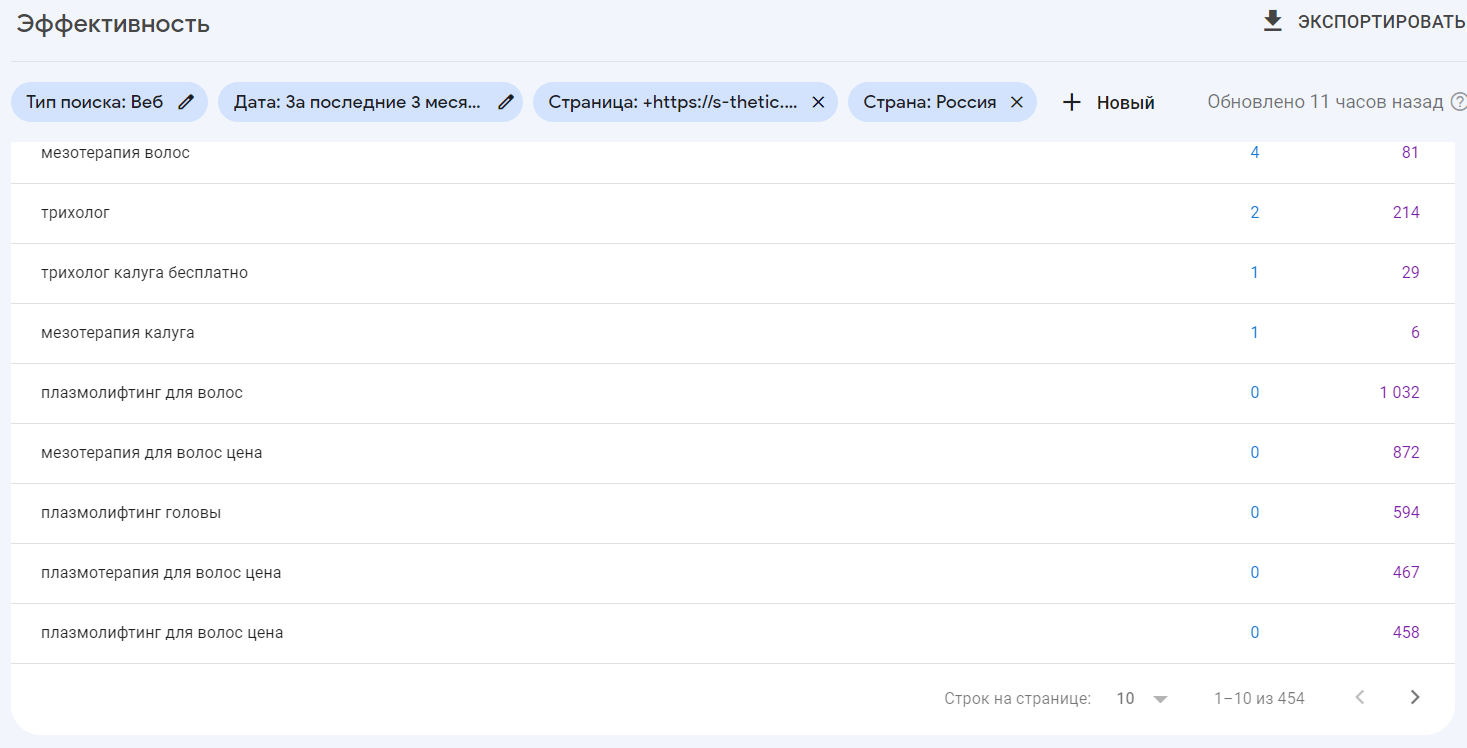
Готово, мы получили перечень фраз, по которым наша страница была показана в поиске. Обратите внимание на к-во ключевых слов на скрине. Наша задача - выяснить, все ли целевые ключевые слова мы использовали на странице или её можно улучшить.
2. Экспортируем перечень фраз и загружаем их в сервис для анализа. В моем случае это keywords explorer в Ahrefs. Начинаем отбор ключевых слов с анализом SERP. Сохраняем фразы в итоговый список.
3. Теперь нам нужно сопоставить наш текст на странице с учетом всех заголовков h1-h6 и мета-теги с нашим списком из пункта 2. Это можно сделать через онлайн сервис, например overlead.me, или написать собственный тул.
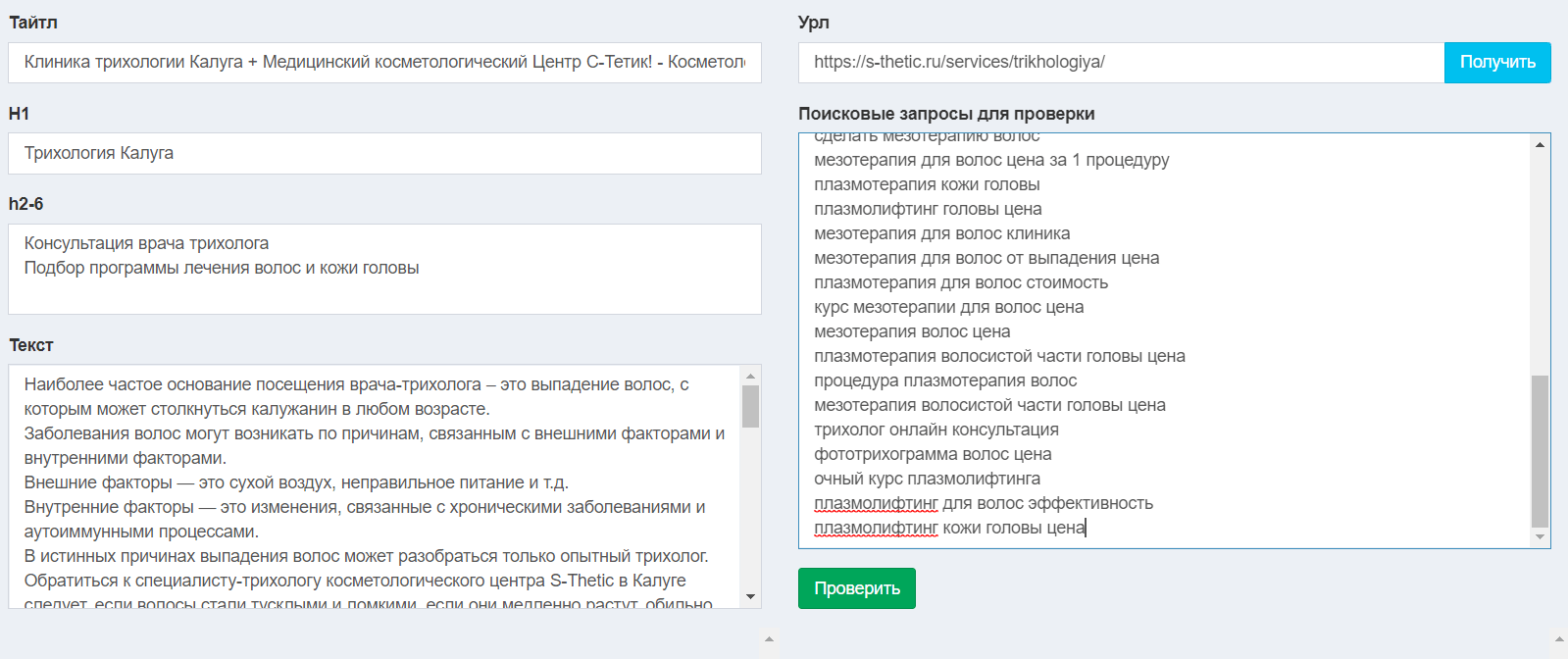
Вводим URL, парсим мета-теги и контент. В окно справа копируем отфильтрованные ключевые слова из пункта 2, жмем кнопку "проверить".
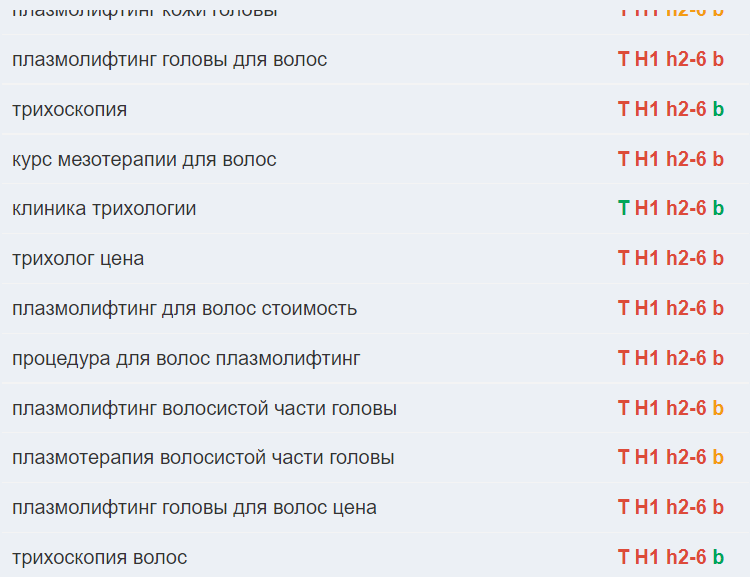
Довольно просто и наглядно получаем результат по каждой фразе и смотрим что можно улучшить, готовим ТЗ на доработку контента и занимаем ТОП в поиске.