Парсинг сайтов для бизнеса: автоматизация, фишки и лайфхаки
 Артём Акулов
Артём АкуловПриветствую!
В этой статье я подробно расскажу что такое парсинг сайтов, зачем он нужен бизнесу, а также какими библиотеками, методами, приёмами и лайфхаками пользуюсь лично я.
Или послушать, доступно на следующих платформах: Яндекс.Музыка, Apple Podcasts, Spotify.
Рекомендую посмотреть стрим, там были интересные вопросы от зрителей, а также практика:
- Парсинг vc.ru и aviationstack по API.
- Парсинг сайта с помощью нейросети.
- Парсинг исходящих ссылок сайта и поиск дроп-доменов.
- Настройка краулера для любого сайта, парсинг и анализ всех данных.
Написать мне в Telegram: https://t.me/akulovartem
Рекомендую подписаться на мои каналы в Telegram, тем самый актуальный контент по парсингу сайтов, SEO и накрутке ПФ, никакой воды и рекламных постов:
- Telegram-канал по парсингу сайтов - https://t.me/ScrapeProfy
- Telegram-канал по SEO и накрутке ПФ - https://t.me/akulov_pro
Ну что, поехали за орехами!
Что такое парсинг сайтов?
Это автоматизированный, массовый сбор общедоступных (публичных) данных, преимущественно с веб-сайтов. Хотя данные можно извлекать и из приложений, основным источником являются именно сайты.
Задачи парсинга включают отслеживание сайтов конкурентов, структурирование данных и сбор контактной информации (например, телефонов, email-адресов) в массовом порядке для маркетинговых активностей. Собранные данные могут использоваться для обзвонов кол-центрами, email-рассылок и других целей.
Зачем парсинг сайтов нужен бизнесу?
Парсинг сайтов открывает множество возможностей для бизнеса, позволяя решать самые разнообразные задачи. Вот лишь некоторые из них:
- Актуализация ассортимента: автоматический сбор информации о новых товарах у поставщиков.
- Сравнение цен и прайс-листов: мониторинг ценовой политики конкурентов.
- Поиск акций и поставщиков: оперативный перехват выгодных предложений на рынке и их отслеживание.
- Мониторинг рынка: анализ трендов в различных сферах, например, в e-commerce (Amazon, Ozon, Wildberries, Avito, и т.д.).
- Наполнение собственного сайта контентом: извлечение и структурирование информации с сайтов поставщиков (с возможностью последующей переработки с помощью нейросетей).
- Сбор базы данных потенциальных клиентов: поиск контактной информации целевой аудитории, от телефонов и e-mail до контактов ЛПР.
- Автоматизация ценовых стратегий: автоматический пересчет собственных цен на основе данных о ценах конкурентов.
- Анализ контента и SEO-показателей: поиск проблем внутренней оптимизации, выявление тем, интересных аудитории, на основе анализа популярных блогов и других ресурсов (например, vc.ru).
Почему парсинг сайтов важен для бизнеса?
В ситуациях, когда объем необходимой информации невелик, ее сбор вручную может быть оправдан. Однако, если возникает потребность в постоянном, регулярном сборе и обработке значительных объемов данных, парсинг становится незаменимым инструментом, обеспечивая следующие преимущества:
- Кратно экономит время: автоматизация процессов сбора и обработки данных существенно сокращает временные затраты.
- Высокая точность и качество данных: парсинг данных из авторитетных источников, таких как специализированные базы данных или картотеки арбитражных судов, обеспечивает высокую достоверность информации.
- Регулярное обновление и всегда свежие данные: парсеры могут быть настроены на автоматическое обновление данных с заданной частотой (например, каждый час или каждый день).
- Быстрая масштабируемость: возможность одновременного сбора данных из множества источников или многопоточный парсинг крупных сайтов.
- Экономия ресурсов: автоматизированные парсеры способны заменить работу целой команды специалистов, выполняющих аналогичные задачи вручную. Расходы на услуги парсинга несопоставимо ниже затрат на зарплату офисных сотрудников.
Как выбрать инструменты для парсинга и вытащить данные с любого сайта конкурента?
Стоит отметить, что я в основном использую Python для парсинга сайтов. Поэтому всё, что представлено в этой статье - касается именно этого языка программирования.
Моя задача - дать общее представление о методах и приёмах, а дальше выбор за вами. Каждая библиотека имеет множество нюансов, которые можно изучать до бесконечности.
И так, выбор конкретных библиотек и инструментов для парсинга зависит от ряда факторов:
- Определить тип контента сайта: статический или динамический.
- Определить тип данных, которые нужно извлечь: текст, графика, видео, таблицы, и т.д.
- Изучить HTML-структуру сайта через Devtools.
- Определить уровень защиты сайт от парсинга.
- Определить масштаб собираемых данных.
- Посчитать сопутствующие расходы на сервера и прокси.
Парсинг статических сайтов и API
Для парсинга статических веб-сайтов и работы с API я рекомендую использовать связку библиотек Requests и Beautiful Soup (bs4).
- Requests: представляет собой HTTP-клиент для Python, который используется для отправки HTTP-запросов (GET, POST и др.) и получения данных с веб-сайтов. Эта библиотека позволяет поддерживать одно соединение на протяжении нескольких запросов, управлять заголовками (headers) и user-agent. Рекомендую настраивает ротацию user-agent и referer в заголовках, чтобы имитировать поведение реального пользователя, это позволяет обходит простейшую защиту при парсинге.
- Beautiful Soup (bs4): библиотека для парсинга XML и HTML-документов. Она позволяет извлекать данные с веб-страниц с помощью несложного синтаксиса, обеспечивая удобную навигацию по DOM-дереву (структуре сайта), поиск элементов по классам, тегам и идентификаторам. BS4 отлично справляется с парсингом текстового контента, заголовков, ссылок и изображений. Важно отметить, что bs4 самостоятельно не может получить HTML-код страницы, для этого и необходимо использовать Requests.
Эта связка абсолютно не подходит для парсинга динамических сайтов, так как не обеспечивает эмуляцию браузера и рендеринг JavaScript. Она также неэффективна для сайтов с высоким уровнем защиты.
В этом случае нужно использовать более продвинутые инструменты, о которых я расскажу далее.
Парсинг динамических сайтов
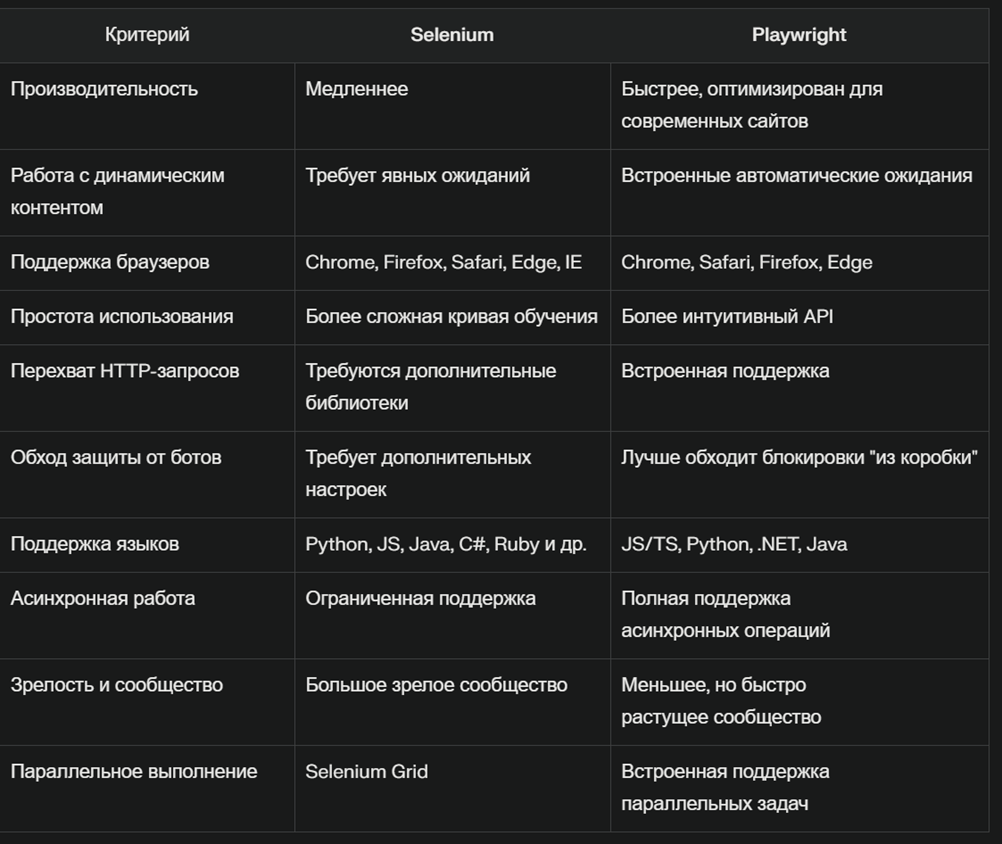
Для работы с динамическим контентом и обхода более серьезных систем защиты я использую библиотеки для автоматизации браузера, такие как Selenium и Playwright.
- Selenium: довольно старая, но по-прежнему поддерживаемая библиотека для автоматизации действий пользователя в браузере. С помощью Selenium можно загружать динамический контент, осуществлять навигацию, скроллить страницы, кликать на элементы, авторизоваться и выполнять другие действия, имитируя реального пользователя. Selenium поддерживает ожидание загрузки определенных элементов на странице и выполнение пользовательского JS-кода. Несмотря на свою эффективность при работе с динамикой и обходе защиты, Selenium работает медленно и требует больше ресурсов (особенно при эмуляции браузера с графическим интерфейсом). Необходимо также следить за утечками памяти при длительной работе и вовремя дропать процессы.
- Playwright: более современная библиотека от Microsoft, изначально предназначенная для тестирования веб-приложений, но активно используемая и для парсинга динамических сайтов.
Playwright является более производительным и удобным в использовании по сравнению с Selenium и он мне намного больше нравится и им я пользуюсь на постоянке. У него есть множество преимуществ:
- Мультибраузерная поддержка: Chromium, Firefox и WebKit через единый API.
- Встроенные умные ожидания перед выполнением действий.
- Возможно контролировать HTTP-запросы и ответы.
- Расширенные возможности эмуляции: устройства, геолокация, разрешения и т.д.
- Отлично подходит для парсинга динамических сайтов, часто обходит системы защиты без доп. настроек.
- Асинхронность, высокая производительность, обработка нескольких операций без блокировки основного потока.
Опять же, можно обойти системы защиты, получить HTML-контент, а затем передать его для парсинга данных в BS4 или Scrapy, что сильно сэкономит ресурсы и увеличит скорость работы парсера.
Как обойти механизмы защиты сайтов от парсинга?
Многие крупные и не очень сайты активно противоборствуют парсингу данных. В этом блоке я расскажу о основных методах обхода защиты для парсинга статических и динамических сайтов.
Для Requests + BS4:
- Обязательная настройка HTTP-заголовков (headers). Делается в пару кликов.
- Добавление случайных задержек между запросами для предотвращение бана от web-сервера.
- Использование мобильных прокси с ротацией IP-адресов (особенно актуально для парсинга Telegram и сложных сайтов, хотя в большинстве случаев достаточно заголовков и ротации user-agent).
Для Selenium:
- Те же меры, что и для requests+bs4.
- Ставим undetected-chromedriver.
Для Playwright:
- Те же меры, что и для requests+bs4.
- Ставим Patchright.
- Настраиваем подмену геолокации.
- Настраиваем расширенные возможности эмуляции (рандомизация действий мышью, нажатий клавиш).
- В тяжелых случаях требуется настраивать эмуляцию fingerprints, cookies, подключать различные плагины в Chrome.
- Подключить в код решение капчи (например, Рукапча).
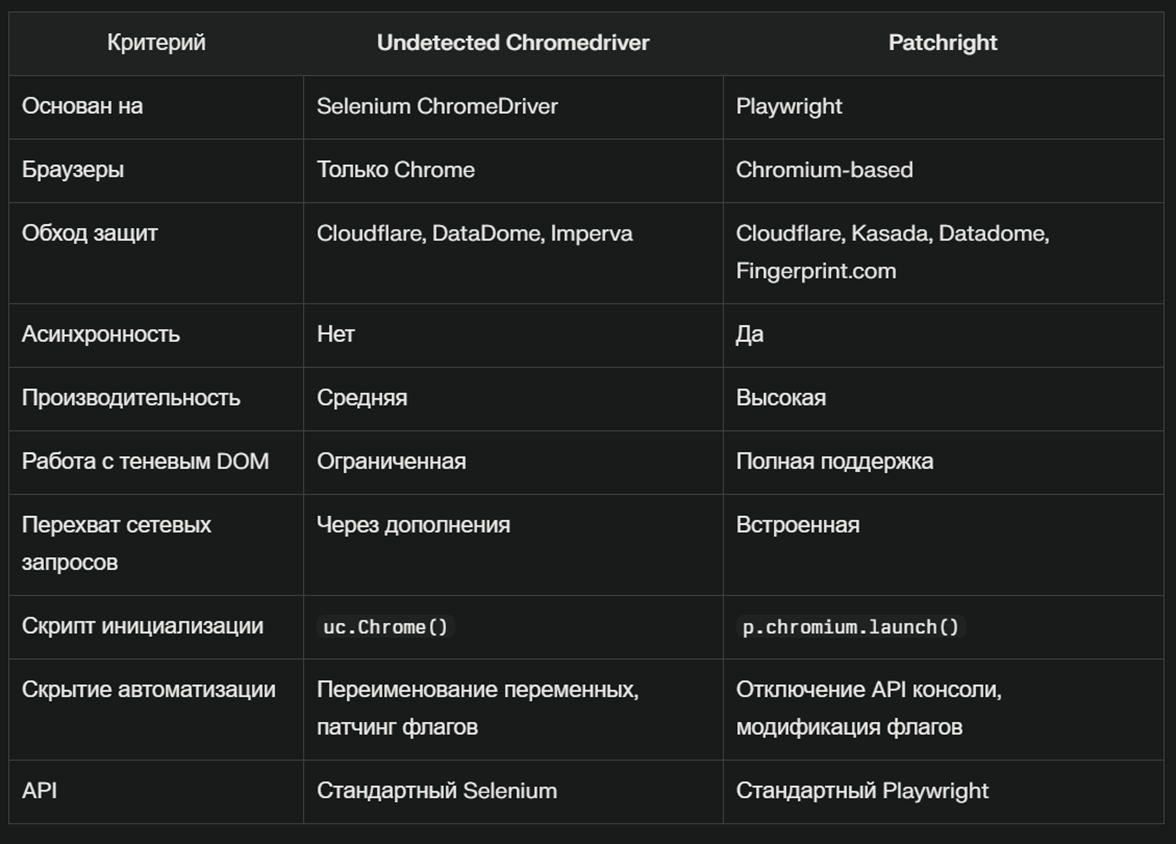
Что такое Undetected Chromedriver и Patchright?
Undetected Chromedriver - представляет собой модифицированную версию Selenium ChromeDriver.
Фишки UCD: переименовывает переменные Selenium, чтобы они соответствовали переменным реальных браузеров, обходит Cloudflare, DataDome, Imperva, Distil Networks, корректно управляет cookies и сессиями, пропатчены флаги.
Patchright - это модифицированная версия Playwright.
Фишки Patchright: устранена утечка runtime.enable, отключена Console API, удалены флаги, выдающие автоматизацию, обходит Cloudflare, Kasada, Akamai, Datadome, Fingerprint.com, CreepJS, не требует дополнительной настройки для базовой маскировки автоматизации, значительно меньше палится как headless браузер в тестах, поддерживает только браузеры на Chromium.
Как парсить сайты с помощью нейросетей: обзор ScrapeGraphAI и Crawl4AI
Парсинг сайтов с помощью нейронок оправдан, когда у нас очень много самых разношерстных сайтов, но нам, например, нужно парсить с них e-mail адреса.
В этом случае не нужно заморачиваться с анализом кода сайтов, нейросеть сама найдет нужную информацию и предоставит ее нам за считанные секунды.
ScrapeGraphAI - библиотека, которая использует LLM для интеллектуального извлечения данных с сайтов.
Фишки ScrapeGraphAI: автоматически адаптируется к структуре сайта, сокращает время на обслуживание кода парсера, извлекает данные из HTML, JSON, XML, совместимость с большим количеством AI сервисов (OpenAI, Claude, и др.).
Основная проблема при использовании ScrapeGraphAI - затраты на токены AI-сервисов. Если имеется мощный свободный сервер, то можно поставить нейросеть в несколько кликов и использовать её абсолютно бесплатно. Об этом я расскажу в следующем блоке.
Crawl4AI - асинхронный парсер, оптимизированный для LLM.
Фишки Crawl4AI: асинхронность, выходные форматы JSON, очищенный HTML, Markdown, очень высокая скорость работы, полная настройка параметров для обхода блокировок, сохранение профилей с состояниями аутентификации, извлекает метаданные, медиа-контент и ссылки, интеллектуальная фильтрация контента, гибкие стратегии работы с HTML-контентом.
Как установить нейросеть на свой компьютер?
LM Studio – бесплатный софт, позволяет запускать Llama, DeepSeek, Mistral, Phi прямо на ПК или собственно сервере.
Фишки LM Studio: локальный запуск нейросетей на своем железе, простая установка и администрирование, лёгкая интеграция по встроенному API с другими приложениями.
Желательно наличие мощного (от 24 GB) GPU от Nvidia. Минимальное количество ядер ЦП - 8, RAM - от 32 GB.
Мои лайфхаки для парсинга сайтов
В повседневной работе я использую множество сервисов и инструментов. Тут я хочу поделиться одними из самых интересных.
Crontab UI - веб-интерфейс для удобного управления задачами CRON прямо из браузера, что избавляет от необходимости запоминать сложные команды или каждый раз редактировать файл через консоль. Мониторинг состояния парсеров, автоматические бекапы, параллельный запуск парсеров.
Jsonformatter - который форматирует, валидирует и делает визуально читабельными JSON-файлы и ответы серверов. Идеален для анализа и отладки JSON. Сразу показывает ошибки, структуру, ускоряет обработку данных.
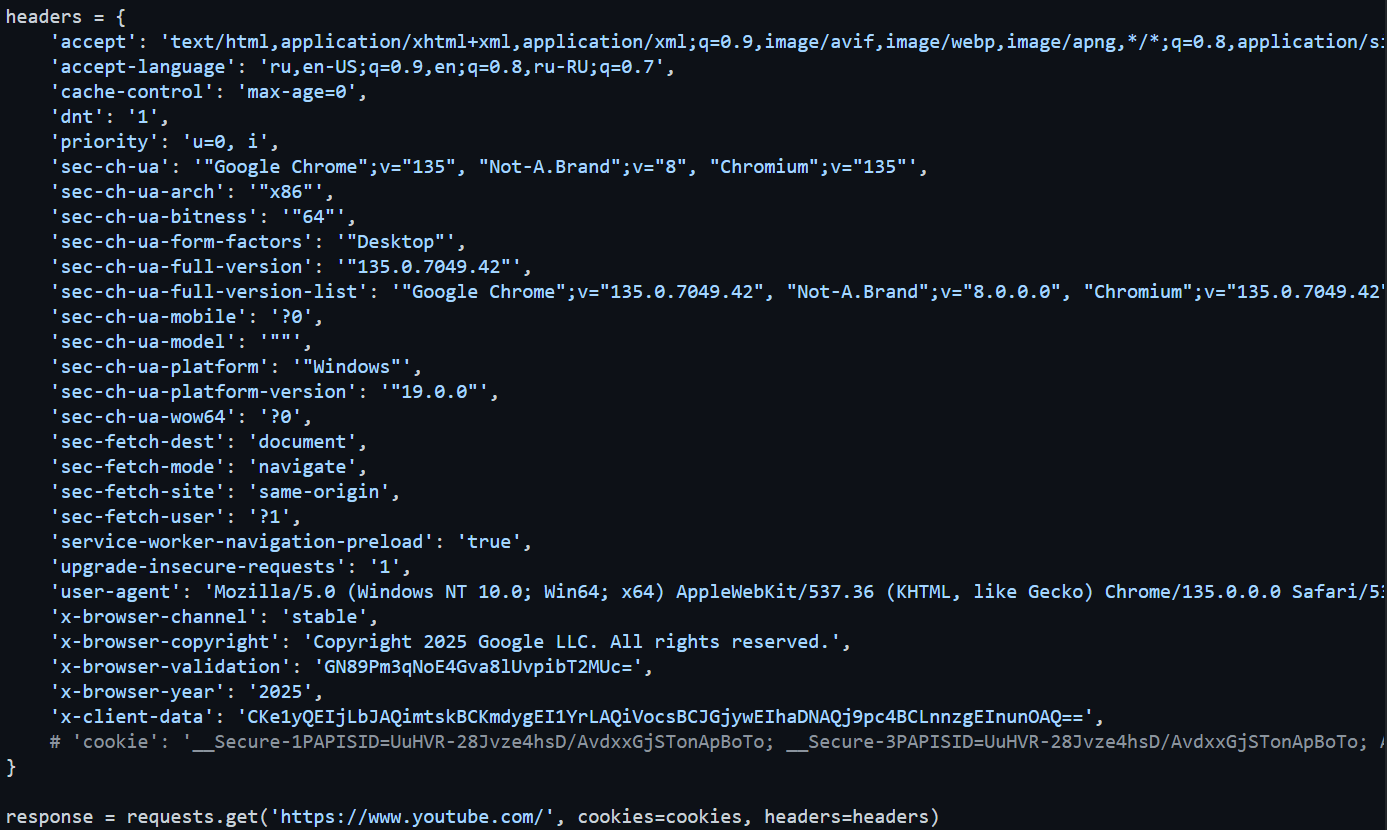
Curlconverter - мгновенно конвертирует HTTP-запросы (например, из Chrome DevTools или Postman) в код на Python. Использую для скоростного создания парсеров и быстрого обхода блокировок.
Красивые заголовки headers вместе c cookies делаются следующим образом:
- открываем нужный сайт, который хотим парсить, нажимаем F12, попадаем в Devtools;
- переходим во вкладку Network и обновляем страницу сайта;
- находим самый первый запрос, кликаем на него ПКМ и выбираем Copy as cURL (bash)
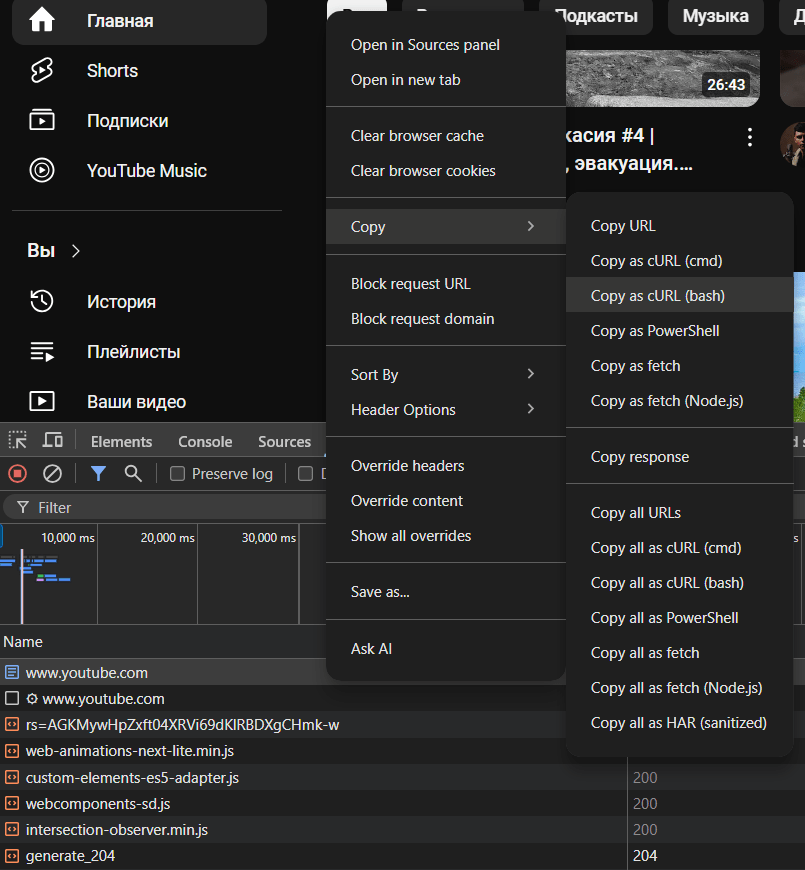
- вставляем содержимое буфера обмена в curlconverter и получаем вот такую красоту за доли миллисекунд.
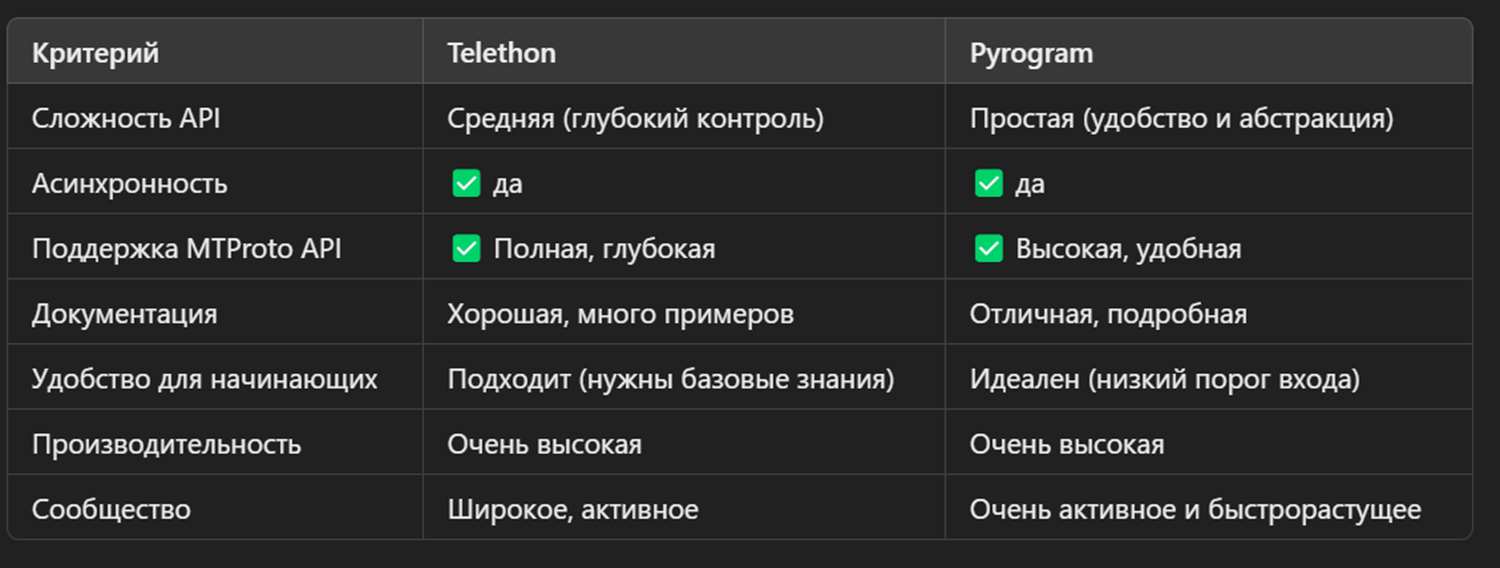
Парсинг Telegram: обзор фреймворков Telethon и Pyrogram
Telethon - асинхронный фреймворк, который предоставляет полный доступ к Telegram API, позволяя создавать сложные автоматизированные решения, от простых скриптов до ботов и клиентских приложений.
Фишки Telethon: асинхронность, высокая производительность при работе через множество аккаунтов, парсит группы, каналы и чаты, автоматически отправляет сообщения, используется для разработки сложных Telegram-ботов, часто используется для мониторинга активности пользователей и конкурентов в Telegram.
Pyrogram - ориентирована на разработку простых приложений, ботов и автоматизаций для Telegram. Продуманный API.
Фишки Pyrogram: интуитивный API, асинхронность, удобно скачивать/загружать медиа и файлы, часто используется для создания ботов в Telegram любой сложности.
Парсим Youtube одной строчкой кода
Для парсинга видео, каналов, и целых плейлистов с Youtube и не только я использую библиотеку YT-DLP.
YT-DLP поддерживает тысячи сайтов, можно парсить даже Первый канал (ну мало ли).
Для успешного парсинга без блокировок нам нужны cookies соответствующего сайта. Их можно получить за секунду с помощью простого расширения для браузера Chrome. Я использую вот это. Экспортировать в txt-файлик нужно в формате Netscape.
Приведу пример основных команд для парсинга Youtube:
- Скачать видео по ссылке в папку Загрузки:
yt-dlp -o 'C:\Users\Admin\Downloads\%(title)s.%(ext)s' --cookies 'C:\Users\Admin\Desktop\cookies.txt' https://www.youtube.com/watch?v=6t08sgiGOWY- Скачать весь плей-лист:
yt-dlp -o '%(playlist_index)s - %(title)s.%(ext)s' <ССЫЛКА НА ПЛЕЙЛИСТ>- Скачать все видео с канала:
yt-dlp -o '%(uploader)s/%(playlist)s/%(playlist_index)s - %(title)s.%(ext)s' https://www.youtube.com/@КАНАЛ/videosВместо заключения
Парсинг сайтов – это мощный и многофункциональный инструмент, который приносит огромную пользу бизнесу в самых разных областях.
От анализа конкурентов и сбора маркетинговых данных до автоматизации рутинных процессов и получения ценной информации для принятия стратегических решений – возможности парсинга практически безграничны.
Современные технологии, включая мощные библиотеки Python и возможности искусственного интеллекта, делают процесс сбора и анализа данных с веб-сайтов все более эффективным и доступным. В современных реалиях однозначно нужно уметь пользоваться нейросетями для ускорения написания и отладки кода парсеров.
У меня ещё очень много чего есть рассказать про парсинг сайтов, AI-агентов и RAG-приложения, так что кому интересно - подписывайтесь на меня на vc.ru и в Telegram.
Благодарю за внимание и до встречи!